Details
HTML Page Content Extractor
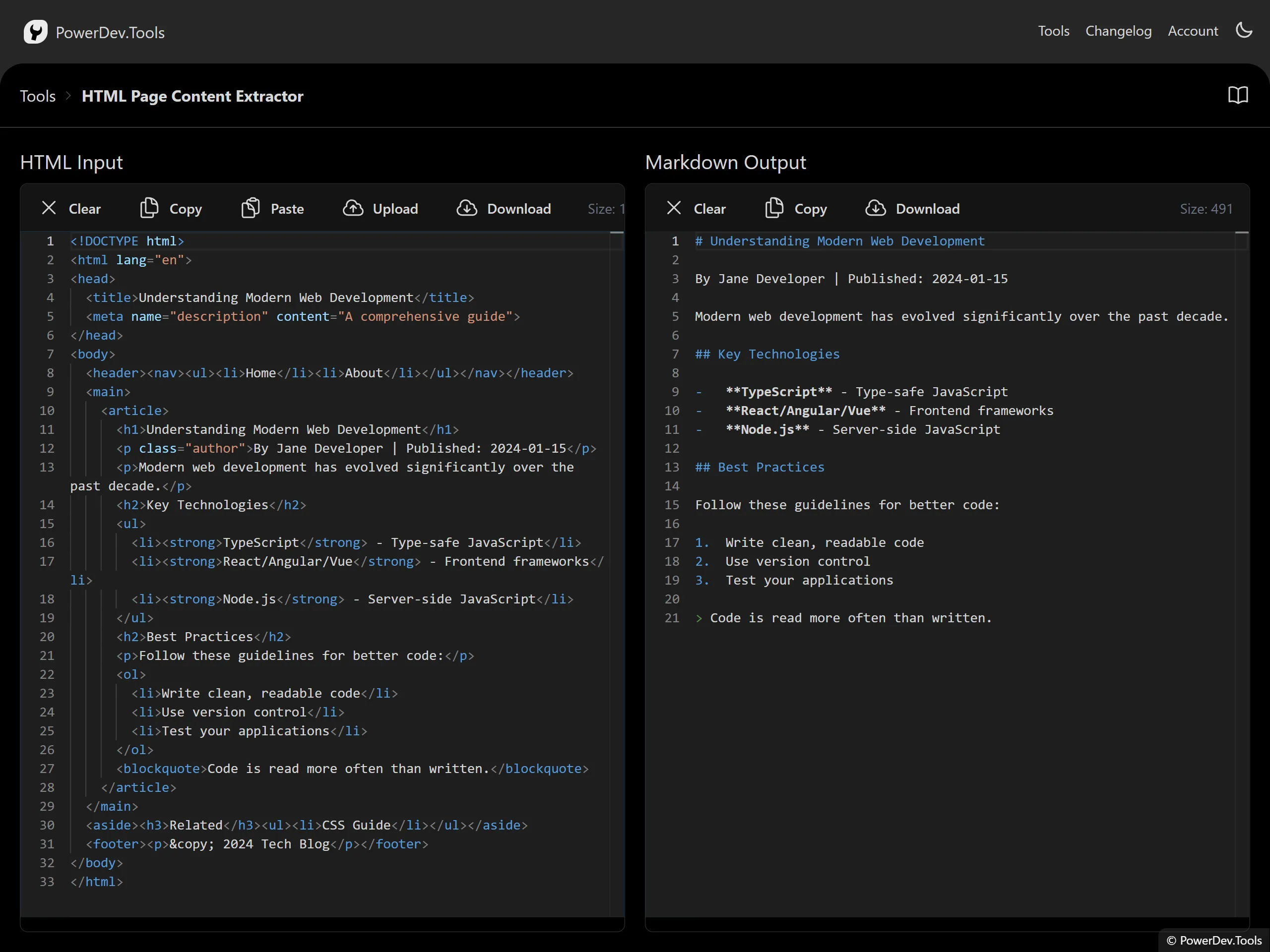
Overview
The HTML Page Content Extractor is a tool that extracts readable text content from complex HTML pages and converts it to clean, human-readable Markdown format.
This tool is particularly useful when you need to:
- Extract main article content from web pages
- Convert HTML documentation to Markdown
- Clean up HTML content for further processing
- Prepare web content for LLM (Large Language Model) processing
- Archive web content in a readable format
Features
- Intelligent Content Extraction: Uses Mozilla's Readability.js algorithm to identify and extract the main content from web pages
- Clean Markdown Output: Converts HTML to well-formatted Markdown, removing ads, navigation, footers, and other irrelevant elements
- Automatic URL Resolution: Converts relative URLs to absolute URLs when a base URL is provided
- Metadata Extraction: Extracts page metadata including title, author, excerpt, and publication date
How to Use
- Paste your HTML source code into the left input panel
- The tool will automatically extract the readable content and convert it to Markdown
- The output will appear in the right panel as clean Markdown text
- Copy the output for your use
Example Use Cases
- Extracting blog post content for archiving
- Converting web documentation to Markdown files
- Cleaning up HTML emails for text processing
- Preparing web content for AI/ML training data
- Creating readable versions of web pages for accessibility